https://docs.ucloud.cn/database/uddb/concepts/method
传统单机数据库面临的挑战
以电商网站为例,在网站创建之初,日均访问量可能只有几百到几千人,这时整个业务后台可能就一个数据库,所有业务表都放在这个数据库中,一台普通的服务器就可以支撑,而且这种架构对业务开发人员也非常友好,因为所有的表都在一个库中,这样查询语句就可以灵活关联了,使用起来很便捷。如图1所示,所有业务表都在一个数据库中。

但是随着业务的不断发展,每天访问网站的人越来越多,数据库的压力也越来越大。通过分析发现,所有的访问流量中,80%以上都是读流量,只有20%左右的写流量,这时可以通过读写分离来缓解数据库的访问压力。如图所示为读写分离,
什么是UDDB?

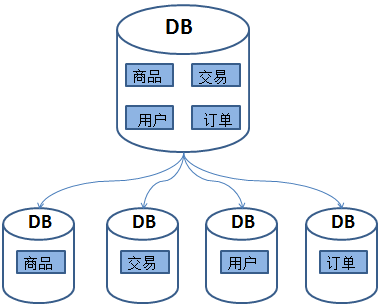
由于网站的访问量越来越大,尽管采取了读写分离的方式,但随着数据库的压力继续增加,数据库的瓶颈越来越突出。这时我们发现,我们的网站演进到现在,交易、商品、用户的数据都还在同一个数据库中。然而在这个巨大而且臃肿的数据库中,表和表之间的数据很多是没有关系的,也不需要JOIN操作,理论上就应该把它们分别放到不同的服务器,如图所示为垂直分库。
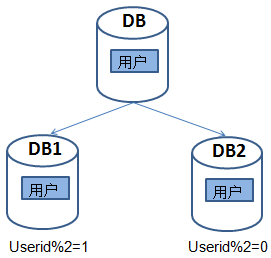
随着业务的不断增长,我们发现交易、商品、用户这些库都变得巨大无比,单机数据库已经无法满足业务的继续增长,这时可以考虑对这些表进行水平拆分,即同一个表中的数据拆分到两个甚至多个数据库中。以用户表为例,数据可以根据userid的奇偶来确定数据的划分。把id为奇数的放到DB1,为偶数的放DB2。如下图为水平分表
单机MySQL面临的挑战
容量和性能问题
业务存储的数据量增多和访问量增大,都构成对单机数据库的挑战;在大数据时代,传统的单机数据库在容量和性能上,都存在瓶颈,明显不能满足业务发展的要求;
成本问题
单机数据库通过Scale-up的方式,采用高端存储和小型机设备,能够一定程度解决容量和性能问题,但带来的问题是成本昂贵,业务成本曲线快速上升。
运维风险问题
数据量达到一定量级后,单机数据库的数据库备份、还原等运维操作需要长时间才能完成,失败概率增加,给日常运维工作带来风险。
开源中间件解决方案及其存在的问题
读写分离、垂直拆库、水平分表作为大型网站后台的刚需,市面上有很多中间件可以满足,比较有代表性的有:阿里巴巴的Cobar、MyCAT。然而这些开源中间件都存在以下缺点:
配置复杂
基于开源中间件对一张大表进行水平拆分需要以下六步操作:
部署数据库节点
安装和部署中间件软件(多个)
登录到各数据库节点,创建子表
把子表的信息,配置到每个中间件的配置文件,然后启动
用HAProxy等负载均衡收敛中间件IP,对外提供一个IP
业务正式访问
运维极其不便
基于开源中间件对系统进行扩容需要进行以下几步:

开源中间件使用和运维的复杂性给业务发展造成了非常大的压力,无形中为企业发展带来了很大的负担。
分布式云数据库UDDB
UCloud 分布式数据库(UCloud Distributed Database,简称UDDB)是基于公有云构建的新一代分布式数据库,为用户提供稳定、可靠、容量和服务能力可弹性伸缩的关系型数据库服务。UDDB 高度兼容 MYSQL 协议和语法,支持自动化水平拆分,在线平滑扩缩容,服务能力线性扩展,透明读写分离,OLTP 和 OLAP 融合支持, 具备数据库全生命周期运维管控能力。
UDDB一开始针对OLTP场景推出, 首先解决用户的生产系统在单机数据库上遇到的容量和性能问题; 在解决容量和性能问题后, 用户又进一步有了数据分析的需求,希望能够利用同一套UDDB,就地实现对业务数据的实时分析。为此,UDDB推出了分析节点来满足用户的需求。UDDB的架构设计如下图所示:
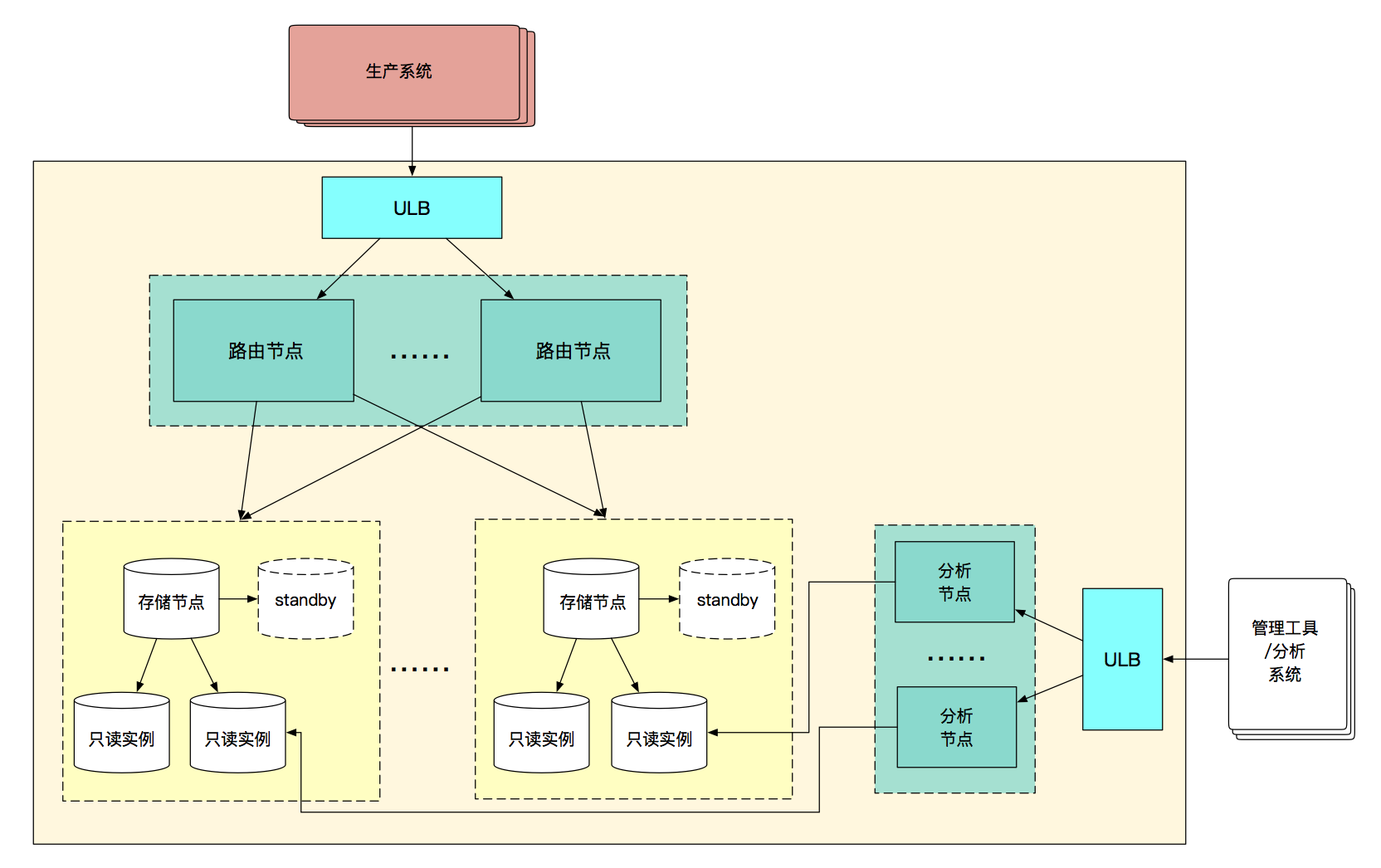
UDDB主要包括三大模块
-
中间件
用来做SQL路由和查询结果的聚合、读写分离、以及对存储节点的管理
-
存储节点
即高可用UDB实例,用来存储分表的数据
-
只读实例
存储节点的从库,普通的UDB实例,只能对其进行读操作
UDDB的主要功能
-
水平分表
UDDB通过水平分表来解决容量瓶颈问题,根据一列数据的值把数据行拆分到多个独立的表里。对于开发人员来说,不再需要关心如何切分数据、如何路由请求等待,只需初始化分片字段(shardkey),直接面向逻辑库表进行编程、专注业务逻辑的实现即可,大大降低了程序的复杂度。
-
读写分离
UDDB的读写分离功能是一种对应用透明的读写分离实现,应用在不需要修改任何代码的情况下,只需要在UDDB控制台中调整读权重,即可将读流量按照需要的比例在存储节点与只读实例之间调整。写流量则统一走存储节点,不分流。
-
垂直建表
可以在创建水平分区表的同时创建普通表,普通表可以指定创建到某个存储节点。
-
在线平滑扩容
UDDB可以通过增加存储节点的方式线性增加系统的容量,系统扩容期间业务可以正常访问,读写请求均可以正常进行,仅在修改中间件路由信息的时候会有0.2秒左右的闪断。
相对开源中间件,分布式云数据库的优势
-
简单易用
提供 Web 控制台,数据库操作简单,基于UDDB对一张大表进行水平拆分只需要以下几步:
- 在控制台上创建一个UDDB实例(一键创建)
- 通过MySQL客户端登录UDDB实例,执行一条create table语句
- 业务访问
-
快速部署
可在线快速部署实例,节省采购、部署、配置等自建数据库工作,缩短项目周期,帮助业务快速上线。
-
弹性扩展
多种规格实例配置;自主升降级,按需扩展;平滑扩展,业务不中断。
-
低成本
稳定的产品,完善的运维和技术支持,相比开源产品总体性价比更高;多种实例规格配置覆盖不同业务规模场景,按需购买;自主控制实例升降配,根据业务量调整资源使用。
-
高可用
UDDB底层数据存储复用了高可用UDB,可用性有保障。
-
在线数据迁移
用户可以通过几行命令将UDB中的数据热迁移到UDDB,业务不受影响。
分布式云数据库的应用场景
- 大型应用
解决百万用户以上的大型应用,如电商、O2O、社交应用,产生海量的数据,普通MySQL架构无法支撑业务增长的问题。
- 物联网数据
在工业监控和远程控制、智慧城市的延展、智能家居、车联网等物联网场景下,传感监控设备多,采样率高,数据存储要求高,超大数据规模存储的问题。
- 文件索引
平台的图片、小文件、视频的数据极大,文件索引为亿级,该类数据通常只有新增、修改、读取、删除操作,分布式数据库可以有效提高提高索引检索的效率。
- 大数据存储
关系型数据是最有价值的数据之一,因大数据分析的需要,需要存储大量历史数据,并解决数据读、写、分析的需求。




