python的抽象类与定义方法
hello 各位小伙伴大家好, 今天想分享一个python如何定义抽象类的手记,众所周知,python是没有interface---接口这个概念的, 在其他的编程语言中,比如golang 如果希望一个函数被反复在不同场景调用,可以使用interface做关联管理,而我们的python其实也有相应的办法,那就是: 通过定义一个基础抽象类,使得继承他的类必须重写需要的函数。这一知识应该不属于python的基础中的,所以如果大家基础还没有打捞,可以移步这里:python2020全栈开发 先把基础打捞。
好,那让我们先说一下如何定义python的抽象类,让我们先提前给出代码(python3),然后解释:
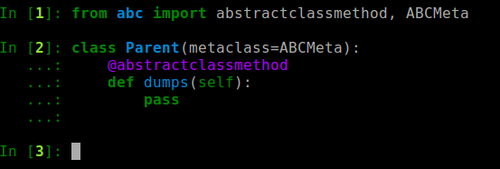
我们来看上图: 通过python的内置模块 abc 倒入 abstractclassmethod 与 ABCMeta,其中前者是一个装饰器函数,后者为显示声明我当前的类为一个抽象类,所以我们在第二行看到了,在parent类的括弧中,定义类metaclass=ABCMeta) 就是生命我是一个抽象类,接下来去定义抽象类中的抽象函数,在每个函数上方添加抽象对应的装饰器,该函数可以没有任何逻辑,直接pass就好,因为他需要未来继承这个抽象类的类去重写他的业务逻辑。
好,现在抽象类已经定义好了,我们来实例化一下试试:
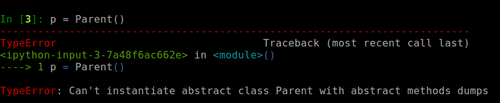
什么情况? 怎么不能实例化呢? 是的, 抽象类,或者说含有抽象函数的类是不能实例化的,必须要重写类函数才可以,所以我们在继承了抽象类后,如果不重写这些抽象函数,依然无法实例化,比如:
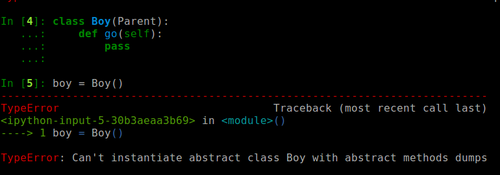
所以我们必须重写抽象函数,才可以实例化,比如:
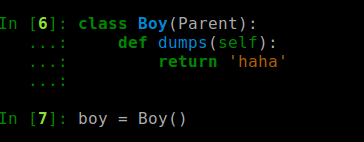
好了,这样就完成了抽象类的定义以及抽象类的使用。 抽象类主要是定义一个函数规则,我们去重复实现在各自的场景下,类似于 其他语言interface的效果。 如果有不准确的地方,也望指正,那么我们今天的分享就到这里。
··································
欢迎关注课程:
《Django入门到进阶-更适合Python小白的系统课程》

相关文章
- SpringCloud- 第十二篇 Zuul概念及原理(一)
- Spark 系列(六)—— 累加器与广播变量
- Spark 系列(四)—— RDD常用算子详解
- Spark 系列(三)—— 弹性式数据集RDDs
- Spark 系列(九)—— Spark SQL 之 Structured API
- Spark 系列(十)—— Spark SQL 外部数据源
- Spark 系列(十一)—— Spark SQL 聚合函数 Aggregations
- Spark 系列(十二)—— Spark SQL JOIN操作
下一篇: Nginx入门教程



